DOM
브라우저가 HTML을 해석하면서 object로 만드는 것을 parsing이라고 한다
object로 만드는 이유는 자바스크립트가 해석할 수 있도록 하기 위해서!
해석한 결과가 DOM Tree를 구성
DOM이란?
Document (= HTML) 을 Javascript가 알아먹을 수 있는 Object 형태로 Modeling 한 거!
DOM이 브라우저에 내장되어 있기 때문에 우리가 HTML 파일의 내용을 JS로 접근, 제어 할 수 있다
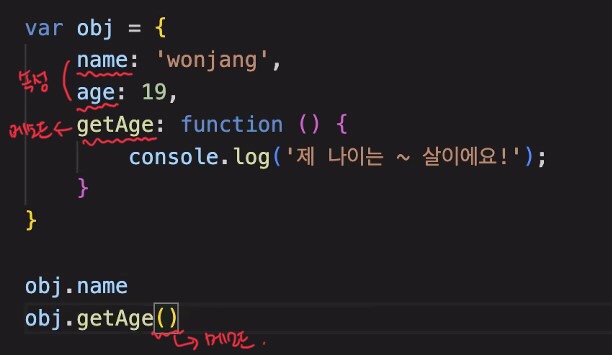
모든 DOM의 node들은 속성과 메소드를 가지고 있다. (node : 마디, 교점)
메소드 : 어디에 접근해서 제어하기 위한 것, 호출의 주체(.앞에 있는 객체)가 있다! 함수는 주체가 없다!
childNodes로 가려면 인덱스를 항상 지정!
*직접적으로 접근하려면 선택할 수 있는 것들이 필요함!
--> select + or
--> 접근 방법 : 태그, id, class
document를 먼저 쓰는 이유는 웹 문서 파일이 document로 시작하기 때문!
getElementById / getElementsByClassName : id는 고유 식별자. 즉, 하나라서 s가 없음. ClassName으로 가져올 경우 여러개이기 때문에, 즉 배열로 가져오기 때문에 인덱스로 접근
querySelector() : id와 class 잘 구분해서 적기
querySelectorAll() : 여러개인 경우
// 해당 id명을 가진 요소 하나를 반환.
document.getElementById("id명")
// 해당 선택자를 만족하는 요소 하나를 반환.
document.querySelector("선택자")
// 해당 class명을 가진 요소들을 배열에 담아 인덱스에 맞는 요소 반환.
document.getElementsByClassName("class명")[인덱스]
// 해당 태그명을 가진 요소들을 배열에 담아 인덱스에 맞는 요소 반환.
document.getElementsByTagName("태그명")[인덱스]
// 해당 선택자를 만족하는 모든 요소들을 배열에 담아 인덱스에 맞는 요소 반환
document.querySelectorAll("선택자명")[인덱스]
새로운 노드를 생성 = 밑으로 가지치기를 더 해보겠다
innetHTML : 바꿀 태그에 접근 먼저 -> document.querySelector('h1').innerHTML = 'TEST'
--> html적인 요소를 넣으면 html 요소는 자동 변환
innerTEXT : doument.querySelecter('h1').innerTEXT = 'TEST' : 따옴표 안에 내용을 그냥 text로 인식
--> 결과가 같아보이지만 다르다!
document.querySelector('h1').innerHTML = '<h2>TEST</h2>' 로 바꾸면 h1 밑으로.
즉, querySelector의 하위요소로 들어간다.
접근을 한 후 제어를 한다!!!!!접근 먼저!!!!!!!!
p.s 강의 다시 집중해서 돌려보고 추가 정리 해야겠다!
'내배캠 4기 React - TIL' 카테고리의 다른 글
| 221205 TIL (0) | 2022.12.05 |
|---|---|
| 221202 TIL - 보충 강의 (1) | 2022.12.03 |
| 221130 TIL (0) | 2022.11.30 |
| 221129 TIL (0) | 2022.11.29 |
| 221128 TIL & KPT (0) | 2022.11.28 |
